さて,クリスマスですね.各分野で行われているアドベントカレンダーも最終日です.
恐縮ながら,最も購読者数の多い,機械学習に必要な高校数学やり直しアドベントカレンダー Advent Calendar 2016を締めくくらせていただこうと思います.
ラストに相応しい記事として,機械学習に必要な高校数学をやり直した後で ニューラルネットワークの学習手順を理解してみようという内容にしてみました
実際に高校生に教えてみて理解してきただけた内容なので,1つ1つみていけば決して難しくないはずです.
また,これは前回の記事の前提知識が必要となります.
今回はかなり噛み砕いて説明を行なっています.そのため,専門に機械学習を学ばれてる方からすると違和感を感じる表現があるかもしれません,ご了承ください.
目次
私が教えた高校生のスペック
「高校生に教えてみた」という記事ですが,どのレベルの高校生かをはじめに明確にしておく必要がありますね.
私がニューラルネットワークの学習手順を教えた高校生は,理系の高校3年生で,数学3までは終了しています
単純な微分の計算,合成関数の微分の計算,そして,単純な微分の計算だけでなく,微分=変化率というイメージが出来ていました
この記事の読者もそのくらいを想定しています.
そして,軽く教えた数学的事項は以下です.
- 偏微分について
- 連鎖律について
- 最急降下法について
これらについてはこの記事内でもかるく触れています.
それでは始めていきましょう.
関数がわかるとなにがよいのか
さて,前の記事で,隠れ層が1層あるニューラルネットワークは,任意の関数を近似することが出来るという話をしました.
ニューラルネットワークを使うと,任意のパルス波を作ることが出来るため,パルス波を組み合わせて関数の近似が可能という話でした.

これは,ニューラルネットワークの重要な性質の1つです.
では,関数を近似することが出来るとなにが嬉しいのでしょうか?
少し考えてみましょう.
関数を使って未来を予想する
例えば,時速2kmで歩いているという状況を考えてあげます.
すると,移動距離は,時間の関数になっていますね.
中学生でもわかる簡単な数学ですが,\(t\)が経過時間,\(f(t)\)が移動距離だとすると, \(f(t)=2t\)となります.
グラフ化してみましょう.

このグラフを見れば,1時間経過すれば移動距離がどれだけなのか?3時間経過すればどれくらいの移動距離があるのかが一目瞭然です.
ここに,関数のすばらしさがあります.
関数さえわかれば,未来が予想できるのです
最初の1時間で2km進み,これからも同じ速さで進むことがわかっている時,3時間後にどれくらい動いているかを予測することが出来ますよね?
3時間後の移動距離を見たければ\(t\)に3を放り込んであげれば良いという話です.
関数の形から,なにかを識別する
他に,関数の形を使って,ものを識別するということにも使われています.
ロボットについているセンサを例に出してみます.
例えば,ロボットが柔らかいものと硬いものに触れている時,センサから送られてくる電気信号の関数の形を記録しておきます.(グラフはあくまで例えばです)

そして,ロボットが実際にものに触れた時に,実際にセンサから送られてくる電気信号の形がどちらに似ているかどうかで,ロボットは硬いものに触れたのか,柔らかいものに触れたのかを判定することが出来ます.

今回のは一例ですが,このように,ニューラルネットワークを用いて関数を近似することができれば,色々,便利なことに応用できるというわけです.
ニューラルネットワークで学習を行う仕組み
それでは,ニューラルネットワークで学習を行う仕組みについて見ていきます.
先程のロボットの例で行くと,ロボットは始めは,どんな信号が硬いものの信号なのかをわかっていません.
そこで,硬いものを触ったときの信号を与えて,その信号の関数の形を覚えさせてあげればいいわけですね.
今回例にするニューラルネットワーク
前の記事で説明した通り,ニューラルネットワークは,重み\(w\)や,バイアス\(b\)を調整し,隠れ層のニューロンを増やすことでどんな関数でも近似することが出来ます.
つまり,実際にお手本となる関数を与えてあげて,その関数に近くなるようにニューラルネットワークの重み\(w\)や,バイアス\(b\)を調整してあげればいいわけです.
前の記事で出てきた,こんな図を覚えているでしょうか?

そうです,パルスを生成するニューラルネットワークですね.
パルスも立派な関数です.
ここでは,話を簡単にするため,このシンプルなニューラルネットワークを考えます.

今回は,隠れ層が1層だけですし,隠れ層にはニューロンが2つしかありません.
シンプルさを最重視ということで,まずはこの簡単なバージョンをしっかり理解しましょう.
誤差逆伝播法
ニューラルネットワークの世界では有名な,誤差逆伝播というものがあります.
誤差逆伝播法とは,お手本と出力を比較することで,重み\(w\)や,バイアス\(b\)を修正していく学習手法のことです

さて,みなさんは比較する時,どうするでしょうか?
例えば,テストの点数の目標を80点としていたとします.
実際の点数が70点だとしたら,「あぁ…10点足りなかった…」となりますよね.
80-70で,10点足りなかった… という計算を行ったはずです
そう,ニューラルネットワークも同じで,引き算をして比較を行います
お手本信号と,出力信号を引いてあげるのです.

しかし,これでは不都合があります.
例えば,テストで目標が80点で,90点を取れた時.
テスト的にはなにも問題はありませんが,一般的にはこれも誤差なのです.
10点の誤差.
目標が80点で,実際の点数が70点だった時,実際の点数が90点だった時.
どちらも,10点の誤差ということで同様に扱うために,2乗してあげます.
すると,どちらも正になりますので,扱いが簡単になります.
差を2乗した値を0に近づけることを考えればよいのですから.

そこで,誤差\(E\)を,\(E=(y-t)^2\)と定義し… たいのですがラストにもうひと踏ん張り
今の目的は,重み\(w\)や,バイアス\(b\)を変化させることで出力信号とお手本信号の誤差をなくすことでしたね
つまり,重み\(w\)や,バイアス\(w\)の変化による,誤差\(E\)の変化量が大事なわけです.
変化量といえば… 微分.
ということで,\(E\)を微分することが多いので,\(E=\frac{1}{2}(y-t)^2\)と定義しておくほうが計算が楽なのです.
さて,やっと\(E\)を定義できたので,あとはこの\(E=\frac{1}{2}(y-t)^2\)を0にするように重み\(w\)や,バイアス\(b\)を修正していくだけです.

数学的準備
さて,誤差\(E\)をなくすことを考えていきたいのですが,その前に少しだけ数学的準備をしましょう.
機械学習に必要な高校数学やり直しアドベントカレンダーなので,高校生でも分かるレベルで書かないといけません.
偏微分
偏微分は,高校数学では習いません.
ただ,そんな難しく考える必要はなく,変数が複数ある場合に,1つだけを変数として扱い,他を定数として扱うというものです.
例えば,\(z(x,y)=x^2+y^2)\)という関数があるとして,例を考えてみましょう.
zをxで偏微分すると,\(\frac{\partial z}{\partial x} = 2x\)となります.
zをyで偏微分すると,\(\frac{\partial z}{\partial y} = 2y\)となります.
簡単ですね.
微分の記号は,\(\frac{d z}{d x}\)と,\(d\)を使いましたが,偏微分は\(\frac{\partial z}{\partial x}\)と,\(\partial \)という記号を使います.
通常の微分の時,\(\frac{d y}{d x}\)とすれば,\(x\)が変化した時,\(y\)がどのくらい変化するかを表していました
\(\frac{d y}{d x}\)が大きいと,\(x\)が変化したら\(y\)が大きく変化するという意味でしたよね.
偏微分でも同じで,\(\frac{d z}{d x}\)というのも,\(x\)以外の変数が一定で\(x\)が変化した時,\(z\)がどれだけ変化するかを表しています.
つまり,今回だとに重み\(w\)や,バイアス\(b\)を変化させて\(E=\frac{1}{2}(y-t)^2\)がどのように変化するかをみたいわけです.
そのため,「とりあえずバイアス\(b\)は一定にしておいて,重み\(w\)を変化させて,エラー\(E\)の変化を確認する」みたいな時に偏微分が使えるということですね
連鎖律
高校で合成関数の微分に関してやったと思います.
合成関数の微分では,例えば\(y\)が\(u\)の関数で,\(u\)が\(x\)の関数であるとき,\(y\)を\(x\)で微分するには以下のようになります.
同じように考えて,\(z\)が\(u\)の関数で,\(y\)が\((x,y)\)の関数である時,\(z\)を\(x\)で,\(z\)を\(y\)で偏微分するには以下のようになります.
簡単ですね!
シグモイド関数の微分
前の記事で出てきた,シグモイド関数を覚えていますか?
そう,\( \frac{1}{1+e^{-x}}\)の形をした関数ですね.
以下の画像を見てもイマイチ思い出せない方は,前の記事を再度ご確認ください

さて,このシグモイド関数を微分するとどうなるでしょうか?
高校3年生で習う,商の微分法を使うと,
なんと,こんなにきれいになりました.
これもシグモイド関数の性質です.
数学事項まとめ
数学事項をまとめました.
これから読み進める上で,「あれ?」ってなったらこちらへお戻りください.
また,具体的に\(\sigma(wx+b)\)を\(w\)で偏微分した結果も載せましたのでご確認ください

どうやって誤差をなくすのか
さて,数学的準備をしている間に本質を見失ってしまった方もいらっしゃいそうです.
今回の目的は,誤差\(E=\frac{1}{2}(y-t)^2\)を0にするように重み\(w\)や,バイアス\(b\)を修正していくことです
さて,ここで例をみていきます.
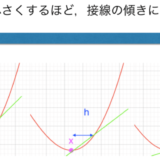
例えば,誤差\(E\)を縦軸,重み\(w_1^1\)を横軸に取ったグラフが以下のような感じだったとします.

これって,小学生でも分かるレベルで明らかですが,誤差の大きさを小さくするには,以下の図のように重み\(w_1^1\)を変化させてあげれば良いです.

さて,これをどうやって数式に持ち込むかという話ですが,実は簡単な話
傾きに注目してあげるのです.
重み\(w_1^1\)を増やすと誤差が少なくなるような範囲では,グラフの傾きが負,つまり\( \frac{\partial E}{\partial w_1^1}\)が0より小さいです.
重み\(w_1^1\)を少なくする誤差が少なくなるような範囲では,グラフの傾きが正,つまり\( \frac{\partial E}{\partial w_1^1}\)が0より大きいです.

つまり,傾きが負なら,\(w_1^1\)を増やす,傾きが正なら,\(w_1^1\)を減らすということは,を\( \frac{\partial E}{\partial w_1^1}\)の符号の反対方向に動かせばよいということで,\(w_1^1\)を\(w_1^1-\alpha \frac{\partial E}{\partial w_1^1} \) (ただし,\(\alpha\)は正)に置き換えてやればいいということが分かります.

これが,よく機械学習で出てくる,最急降下法と呼ばれるものです.
理解さえしてしまえば,そこまで難しいわけでもありません.
例では,\(w_1^1\)を扱いましたが,最後に一般化しておきましょう.
一般化すると,\(w_k^1\)を\(w_k^1-\alpha \frac{\partial E}{\partial w_k^1} \) に更新してやれば良いことになります.
\(w_k^1\)だけではなく,\(w_k^2\)や,\(b_k\),\(b\)も同様に変化させて誤差を少なくしていく必要があります.

つまり,\(w_1^1\)を更新するときの考え方と全く同じやり方で以下の4式が求まります.
- \(w_k^1\)を\(w_k^1-\alpha \frac{\partial E}{\partial w_k^1} \) に更新
- \(w_k^2\)を\(w_k^2-\alpha \frac{\partial E}{\partial w_k^2} \) に更新
- \(b_k\)を\(b_k-\alpha \frac{\partial E}{\partial b_k} \) に更新
- \(b\)を\(b-\alpha \frac{\partial E}{\partial b} \) に更新
この更新を繰り返していくことで,最終的に誤差を0にすることが出来るというわけです.
偏微分を消してみる
さて,誤差をなくしていくためにはどのように重み\(w\)や,バイアス\(b\)を修正すればよいかがわかりました.
ただ,コンピュータにとって偏微分の形が残っているのは都合がよくありません.
そこで,この偏微分を計算して,微分が残っていない形に持っていきましょう.
まずは,\(w_k^2\)の更新に関してです.
\(w_k^2\)を\(w_k^2-\alpha \frac{\partial E}{\partial w_k^2} \) に更新します.
この偏微分で表されたところは,連鎖律を使うと,
\(\frac{\partial E}{\partial w_k^2} = \frac{\partial E}{\partial y} \frac{\partial y}{\partial w_k^2} = (y-t)(1-y) y u_k \)になります. (詳しくは下の画像を参照)

次に,\(b\)の更新に関してです.
\(b\)を\(b\ – \alpha \frac{\partial E}{\partial b}\)に更新します.
先程と同様に,連鎖律を使うと,この偏微分で表されたところは,\(\frac{\partial E}{\partial b} = \frac{\partial E}{\partial y} \frac{\partial y}{\partial b} = (y-t)(1-y) y \)になります. (詳しくは下の画像を参照)

そして次,\(w_k^1\)の更新に関してです.
\(w_k^1\)を\(w_k^1-\alpha \frac{\partial E}{\partial w_k^1} \)に更新します.
この偏微分で表されたところは,連鎖律を使うと,
\(\frac{\partial E}{\partial w_k^1} = \frac{\partial E}{\partial y} \frac{\partial y}{\partial u_k}\frac{\partial u_k}{\partial w_k^1} = (y-t)(1-y) y w_k^2 (1-u_k) u_k x\)になります. (詳しくは下の画像を参照)

そして最後に,\(b_k\)の更新に関してです.
\(b_k\)を\(b_k-\alpha \frac{\partial E}{\partial b_k} \)に更新します.
先程と同様に,連鎖律を使うと,この偏微分で表されたところは,\(\frac{\partial E}{\partial b_k} = \frac{\partial E}{\partial y}\frac{\partial y}{\partial u_k} \frac{\partial y}{\partial b_k} = (y-t)(1-y) y w_k^2 (1-u_k) u_k \)になります. (詳しくは下の画像を参照)

と,これで偏微分をすべて\(y,t\)などの数字で表せました.
あとは,これをコンピュータで何度も繰り返し重み\(w\)や,バイアス\(b\)を修正していくだけです.

これが,とてもシンプルにした,誤差逆伝播法と呼ばれるニューラルネットワークの学習手法です.
まとめ
高校生に教えたときのをだいたいそのまま言語化したので,かなりシンプルになっており,厳密でない部分もありました.
しかしこれで一応,隠れ層が1のニューラルネットワークに関しては学習の流れがわかったかと思います.
もちろん,隠れ層は一般的には1だけではありませんが,最初に述べた通り,簡単化のために今回は隠れ層が1のニューラルネットワークを扱いました.
基礎的なことはこんな感じなので,これが理解できれば,他の記事で扱われているようなことも割りとすんなり理解できるのではないかと思います.
ちなみに,このような事象をしっかり理解するには手を動かしてみることがもっとも手っ取り早いと思います.この本が楽しくてわかりやすくてめっちゃおすすめです.
中学,高校レベルの数学だけで説明しようとしているところがすごく好印象です.

▼期間限定で無料配布中▼

- 経済的自立を果たす10のステップ
- 時給10円から年商10億円に至る道のり
- 最短で0→1を立ち上げる起業術
- お金持ちになる5つのルール
- すぐに実行できる即金マニュアル
無料特典を受け取るか迷っている方は、こちらの記事「真面目」でも「頭がいい人」でもお金持ちになれないたった1つの理由」をお読みください。